考虑到自己能想起的成语数量实在有限,所以就把这个问题交给计算机来处理吧。
首先,很容易就在网上下载到了一个 access 格式的数据库,经检查实际存储了去重后的四字成语两万九千多个。导出为 txt 格式的文件。
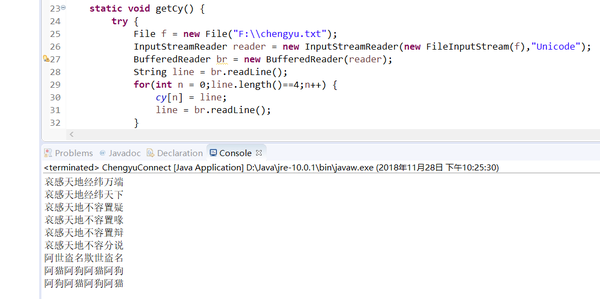
然后打开了 eclipse ,写下了以下代码:
packagecom.example.chengyuconnect;importjava.io.BufferedReader;importjava.io.File;importjava.io.FileInputStream;importjava.io.InputStreamReader;importjava.sql.Connection;importjava.sql.ResultSet;importjava.sql.Statement;importjava.sql.DriverManager;publicclassChengyuConnect{staticString[]cy=newString[30000];staticString[]cy1=newString[30000];staticString[]cy2=newString[30000];publicstaticvoidmain(String[]args){getCy();splitCy();searchCy();}staticvoidgetCy(){try{Filef=newFile("F:\\chengyu.txt");InputStreamReaderreader=newInputStreamReader(newFileInputStream(f),"Unicode");BufferedReaderbr=newBufferedReader(reader);Stringline=br.readLine();for(intn=0;line.length()==4;n++){cy[n]=line;line=br.readLine();}}catch(Exceptione){e.printStackTrace();}}staticvoidsplitCy(){for(inti=0;i<cy.length&&cy[i+1]!=null;i++){cy1[i]=cy[i].substring(0,2);cy2[i]=cy[i].substring(2,4);}}staticvoidsearchCy(){for(inti=0;i<cy.length;i++)for(intj=0;j<cy.length;j++)if(cy2[i]!=null&&cy1[j]!=null&&cy2[i].equals(cy1[j]))for(intk=0;k<cy.length;k++)if(cy2[j]!=null&&cy1[k]!=null&&cy2[j].equals(cy1[k]))System.out.println(cy[i]+cy[k]);}}
大概的思路是:
运行,几秒钟就可以看到所有结果:
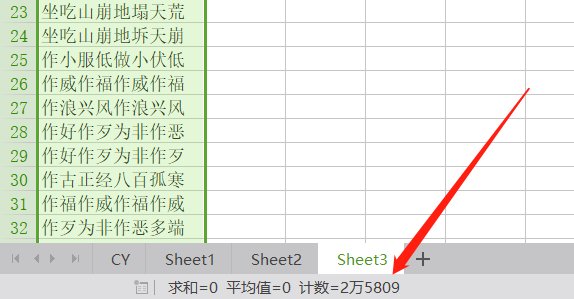
将结果复制粘贴到表格里,数量 2 万 5809:
全部结果就不发出来了,因为不知道知乎是否支持写 20 多万字的回答。
在表格的截图里,还有三个单元表,CY 看起来像是表示成语……嗯,这其实是一个失败的尝试。本想直接在表格里处理,可是没料到 VLOOKUP 函数处理速度太慢,几万条数据直接让表格崩溃了,所以最后就留一张测试部分的截图作为纪念吧。
2018.11.29 更新
感谢 @忠肝义胆吕奉先 在评论中指出回答里的一个问题:在输出的结果中,存在前后两个成语相同的情况,如果认为三个成语是互不相同的成语,则需要在代码中限制输出的是前后不相同的两个成语连接起来的八个字。
除了直接改代码,也可以把结果复制粘贴到表格里,在表格里进行判断和筛选,这样还能发现一批前后两个字互换位置,结果仍是成语的成语。